
mysql中去重 distinct用法
作者:网络转载 发布时间:[ 2017/6/21 9:49:57 ] 推荐标签:MySQL 数据库
在使用MySQL时,有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重复的记录,但是实际中我们往往用distinct来返回不重复字段的条件(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段,例如有如下表user:
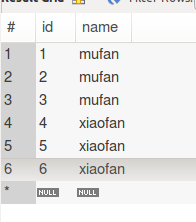
用distinct来返回不重复的用户名select distinct name from user,结果为:
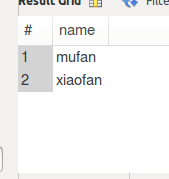
这样只把不重复的用户名查询出来了,但是用户的id,并没有被查询出来,如果想要查询不重复的id和name:select distinct name, id from user
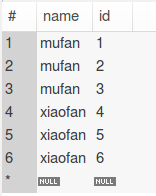
像select distinct name, id from user这样的mysql会把name, id字段都重复的记录过滤掉。
但是sql这样写:select id, distinct name from user,这样mysql会报错
因为distinct必须放在要查询字段的开头。
所以一般distinct用来查询不重复记录的条数。
如果要查询不重复的记录,有时候可以用group by:select id, name from user group by name
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐
在测试数据库性能时,需要注意哪些方面的内容?测试管理工具TC数据库报错的原因有哪些?怎么解决?数据库的三大范式以及五大约束编程常用的几种时间戳转换(java .net 数据库)优化mysql数据库的几个步骤数据库并行读取和写入之Python实现深入理解数据库(DB2)缓冲池(BufferPool)国内三大云数据库测试对比预警即预防:6大常见数据库安全漏洞数据库规划、设计与管理数据库-事务的概念SQL Server修改数据库物理文件存在位置使用PHP与SQL搭建可搜索的加密数据库用Python写一个NoSQL数据库详述 SQL 中的数据库操作详述 SQL 中的数据库操作Java面试准备:数据库MySQL性能优化












 sales@spasvo.com
sales@spasvo.com