
分布式程序的自动化回归测试
作者:网络转载 发布时间:[ 2011/5/17 13:53:51 ] 推荐标签:
分布式系统的抽象观点
一台机器两根线
形象地来看,一个分布式系统是一堆机器,每台机器的屁股上拖着两根线:电源线和网线(不考虑 SAN 等存储设备),电源线插到电源插座上,网线插到交换机上。
这个模型实际上说明,一台机器的表现出来的行为完全由它接出来的两根线展现,不谈电源线,只谈网线。(“在乎服务器的功耗”在我看来是公司利润率很低的标志,要从电费上抠成本。)
如果网络是普通的千兆以太网,那么吞吐量不大于 125MB/s。这个吞吐量比起现在的 CPU 运算速度和内存带宽简直小得可怜。这里我想提的是,对于不特别在意 latency 的应用,只要能让千兆以太网的吞吐量饱和或接近饱和,用什么编程语言其实无所谓。Java 做网络服务端开发也是很好的选择(不是指 web 开发,而是做一些基础的分布式组件,例如 ZooKeeper 和 Hadoop 之类)。尽管可能 C++ 只用了 15% 的 CPU,而 Java 用了 30% 的 CPU,Java 还占用更多的内存,但是千兆网卡带宽都已经跑满,那些省下在资源也只能浪费了;对于外界(从网线上看过来)而言,两种语言的效果是一样的,而通常 Java 的开发效率更高。(Java 是比 C++ 慢一些,但是透过千兆网络不一定还能看得出这个区别来。)
进程间通过 TCP 相互连接
陈硕在《多线程服务器的常用编程模型》第 5 节“进程间通信”中提倡仅使用 TCP 作为进程间通信的手段,这个观点将再次得到验证。
以下是 Hadoop 的分布式文件系统 HDFS 的架构简图。

HDFS 有四个角色参与其中,NameNode(保存元数据)、DataNode(存储节点,多个)、Secondary NameNode(定期写 check point)、Client(客户,系统的使用者)。这些进程运行在多台机器上,之间通过 TCP 协议互联。程序的行为完全由它在 TCP 连接上的表现决定(TCP 好比前面提到的“网线”)。
在这个系统中,一个程序其实不知道与自己打交道的到底是什么。比如,对于 DataNode,它其实不在乎自己连接的是真的 NameNode 还是某个调皮的小孩用 Telnet 模拟的 NameNode,它只管接受命令并执行。对于 NameNode,它其实也不知道 DataNode 是不是真的把用户数据存到磁盘上去了,它只需要根据 DataNode 的反馈更新自己的元数据行。这已经为我们指明了方向。
一种自动化的回归测试方案
假如我是 NameNode 的开发者,为了能自动化测试 NameNode,我可以为它写一个 test harness (这是一个独立的进程),这个 test harness 仿冒(mock)了与被测进程打交道的全部程序。如下图所示,是不是有点像“缸中之脑”?
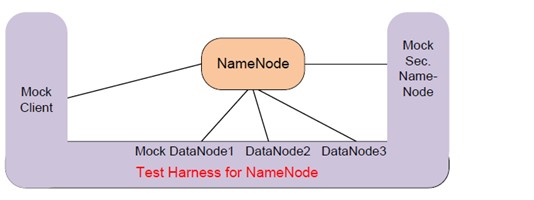
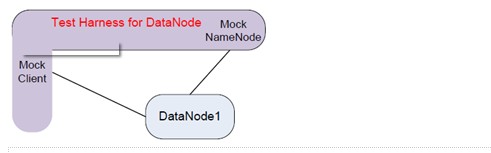
对于 DataNode 的开发者,他们也可以写一个专门的 test harness,模拟 Client 和 NameNode。
Test harness 的优点
*完全从外部观察被测程序,对被测程序没有侵入性,代码该怎么写怎么写,不需要为测试留路。
*能测试真实环境下的表现,程序不是单独为测试编译的版本,而是将来真实运行的版本。数据也是从网络上读取,发送到网络上。
*允许被测程序做大的重构,以优化内部代码结构,只要其表现出来的行为不变,测试不会失败。(在重构期间不用修改 )
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。












 sales@spasvo.com
sales@spasvo.com