
JAVA线程池管理及分布式HADOOP调度框架搭建
作者:网络转载 发布时间:[ 2013/6/25 10:07:51 ] 推荐标签:
基于jeeframework我们封装spring、ibatis、数据库等操作,并且可以调用业务方法完成业务处理。主要组件为:
1、任务集中存储到数据库服务器
2、控制中心负责管理集群中的节点状态,任务分发
3、线程池调度集群负责控制中心分发的任务执行
4、web服务器通过可视化操作任务的分派、管理、监控。
一般这个架构可以应对常用的分布式处理需求了,不过有个缺陷是随着开发人员的增多和业务模型的增多,单线程的编程模型也会变得复杂。比如需要对1000w数据进行分词,如果这个放到一个线程里来执行,不算计算时间消耗光是查询数据库需要耗费不少时间。有人说,那我把1000w数据打散放到不同机器去运算,然后再合并不行了吗?因为这是个特例的模式,专为了这个需求去开发相应的程序没有问题,但是以后又有其他的海量需求如何办?比如把倒退3年的所有用户发的帖子中发帖子多的粉丝转发的高的用户作息时间取出来。又得编一套程序实现,太麻烦!分布式云计算架构要解决的是这些问题,减少开发复杂度并且要高性能,大家会不会想到一个近很热的一个框架,hadoop,没错是这个玩意。hadoop解决的是这个问题,把大的计算任务分解、计算、合并,这不是我们要的东西吗?不过玩过这个的人都知道他是一个单独的进程。不是!他是一堆进程,怎么和我们的调度框架结合起来?看图说话:
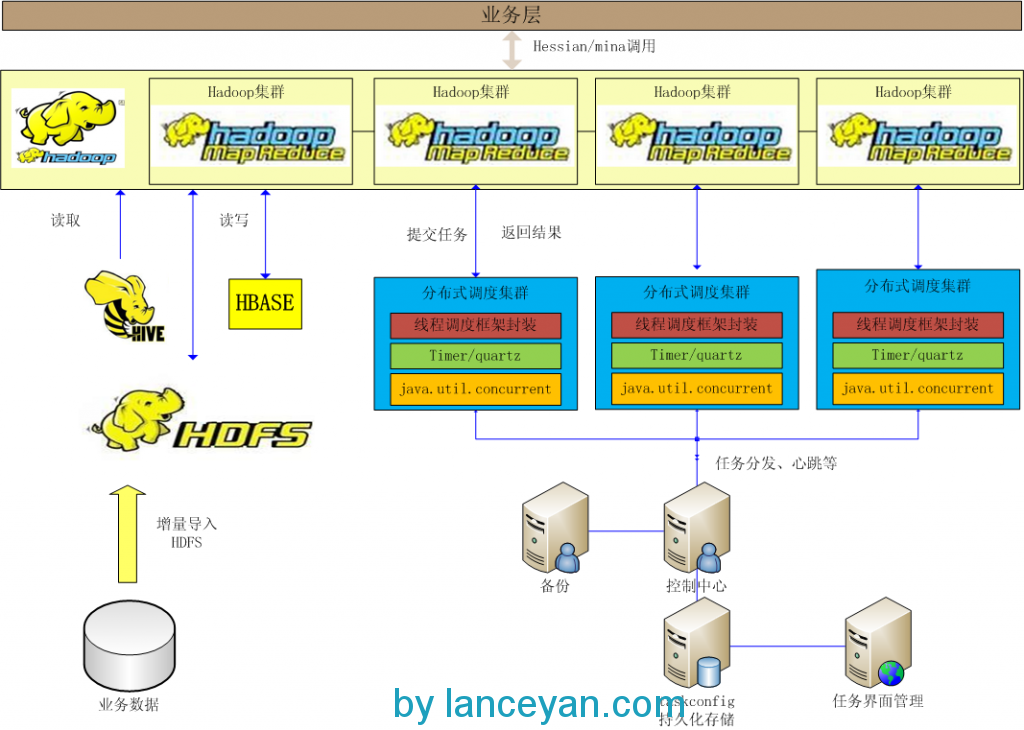
基本前面的分布式调度框架组件不变,增加如下组件和功能:
1、改造分布式调度框架,可以把本身线程任务变成mapreduce任务并提交到hadoop集群。
2、hadoop集群能够调用业务接口的spring、ibatis处理业务逻辑访问数据库。
3、hadoop需要的数据能够通过hive查询。
4、hadoop可以访问hdfs/hbase读写操作。
5、业务数据要及时加入hive仓库。
6、hive处理离线型数据、hbase处理经常更新的数据、hdfs是hive和hbase的底层结构也可以存放常规文件。
这样,整个改造基本完成。不过需要注意的是架构设计一定要减少开发程序的复杂度。这里虽然引入了hadoop模型,但是框架上开发者还是隐藏的。业务处理类既可以在单机模式下运行也可以在hadoop上运行,并且可以调用spring、ibatis。减少了开发的学习成本,在实战中慢慢体会学会了一项新技能。
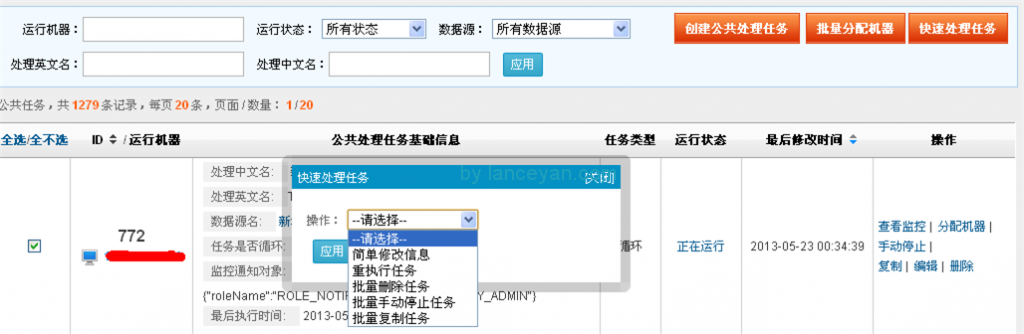
界面截图:
本文转载自:http://lanceyan.blog.51cto.com/5843/1207602












 sales@spasvo.com
sales@spasvo.com