
浅析列式数据库的特点
作者:网络转载 发布时间:[ 2013/7/25 10:51:47 ] 推荐标签:
数据迭代 (Tuple Iteration)
现在的多核CPU 提供的L2 缓存在短时间执行同一个函数很多次的时候能更好的利用CPU 的二级缓存和多核并发的特性。而行式数据库由于其数据混在一起没法对一个数组进行同一个简单函数的调用,所以其执行效率没有列式数据库高。
压缩算法
列式数据库由于其每一列都是分开储存的。所以很容易针对每一列的特征运用不同的压缩算法。常见的列式数据库压缩算法有Run Length Encoding , Data Dictionary , Delta Compression , BitMap Index , LZO , Null Compression 等等。根据不同的特征进行的压缩效率从10W:1 到10:1 不等。而且数据越大其压缩效率的提升越为明显。
延迟物化
列式数据库由于其特殊的执行引擎,在数据中间过程运算的时候一般不需要解压数据而是以指针代替运算,直到后需要输出完整的数据时。
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)
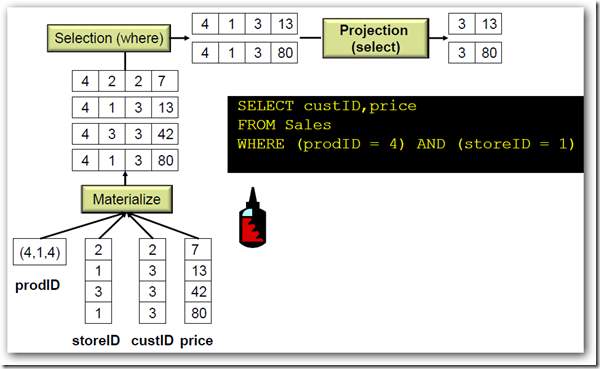
传统的行式数据库运算, 在运算的一开始解压缩所有数据,然后执行后面的过滤,投影,连接,聚合操作
而列式数据库的执行计划却是这样的。
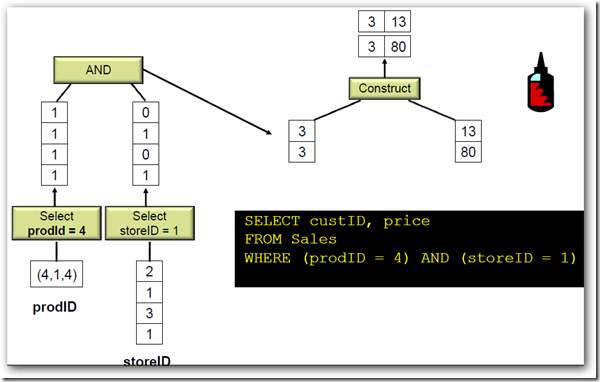
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)
在整个计算过程中, 无论过滤,投影,连接,聚合操作,列式数据库都不解压数据直到后数据才还原原始数据值。这样做的好处有减少CPU 消耗,减少内存消耗,减少网络传输消耗,减少后储存的需要。












 sales@spasvo.com
sales@spasvo.com