
SQL Server优化器特性-动态检索
作者:网络转载 发布时间:[ 2015/2/26 16:05:00 ] 推荐标签:数据库 SQL Server 动态检索
回顾:SQL2012中发生死锁的原因已经向大家解释了,因为隐式转换造成的表扫描扩大了锁规模.但在SQL2008R2中未有同样的现象出现,很显然锁规模没有扩大,原因在于SQL Server的优化器为我们做了额外的事情-动态检索
动态检索:基于索引查找的优势,SQL Server(部分版本)会尝试将一些情形进行内部转换,使得索引检索的覆盖面更广,对其实重要补充.
还是之前那篇的实例,我们在SQL2008R2中看到的update的执行计划如图1-1
Code 生成测试数据
create table testlock
(ID varchar(10) primary key clustered,
col1 varchar(20),
col2 char(200))
go----------create test table
declare @i int
set @i = 1
while @i < 100
begin
insert into testlock
select right(replicate('0',10)+ cast(@i as varchar(10)),10),'aaa','fixchar'
set @i = @i+1
end
go----------generate test data
Code 死锁语句
declare @ID nvarchar(10)
begin tran
select top 1 @ID = ID from testlock with(updlock, rowlock, readpast)
where col1 = 'aaa'
order by id asc
select @ID
waitfor delay '00:00:20'
update testlock set col1 = 'bbb' where id = @ID
commit tran
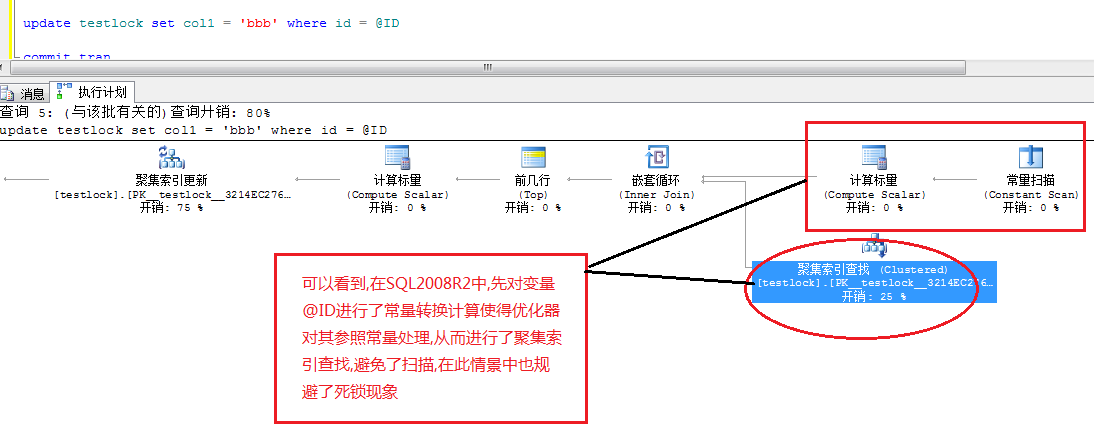
图1-1
可以看到因为SQL Server将变量@ID进行了额外的转换运算,使得其作为数值进行处理,从而进行索引查找以提升效率,这是动态检索的初衷,在此却也同时规避了死锁的发生.
关于动态检索
在进行动态检索时,优化器会将常量,标量的计算的CPU,IO的预估消耗置0,以避免查询子树的大小变化造成可能的执行计划改变,同时将相应的检索数值区间及检索方式作为查询操作的输入进行检索.如图1-2
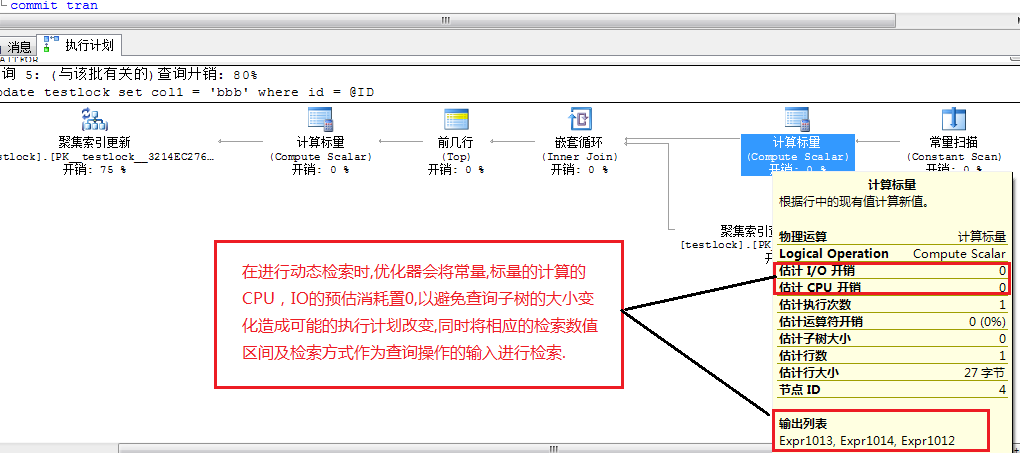
图1-2












 sales@spasvo.com
sales@spasvo.com