
网络运维的本质:可视化
作者:网络转载 发布时间:[ 2015/5/11 10:19:52 ] 推荐标签:网络运维
第二部分,可视化服务度量
“除了上帝,一切人都必须用数据说话”,这是运维人员必须恪守的信条。我写过一篇完整的数据驱动运维的文章《关于数据驱动运维的几点认识》,里面系统地介绍了数据化运维的目的、数据的来源以及如何构建数据体系,等等。
近也在进行一个数据实践,是建立面向应用的端到端数据分析体系,该体系对数据有个标准化的分层归类,从基础设施、上层组件、到应用服务、到接口、再到用户侧,基于应用的拓扑架构,收集各类指标,统一到一个分析平台中展现,如下图所示。
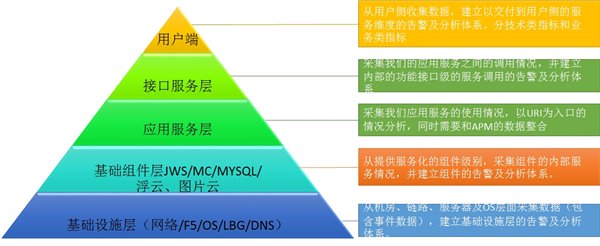
基于这套分层化的数据体系标准,我们也有对应的系统实现,如下图所示。
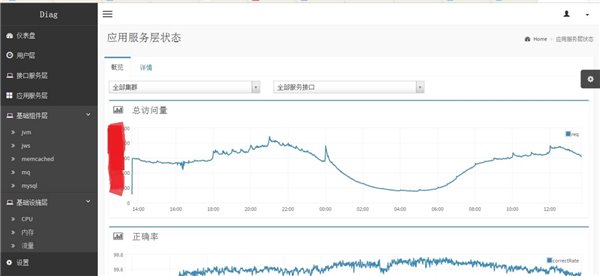
当形成标准的数据采集、分析和展现体系之后,可以向其他应用不断去复制这套方案,大家只需要遵循一套数据标准即可,后数据的采集、分析、展现和告警都是标准化完成。这套数据体系建设完成之后,可以在运维的故障定位、服务优化、架构改进、运维规划等各方面找到应用场景。
此时有人会有疑问如何面向应用把这些数据整合关联起来?我们当前是基于配置文件的静态视图和基于接口调用而生成的动态视图来集成。动态调用视图生成会复杂一点,可以让线上的接口调用统一由名字服务中心来接管调度,抽样对接口调用进行染色,从而生成动态的访问关系。
以上视图能快速发现和定位规模故障,但对于单个用户的故障指标上则应对乏力。此时分布式Trace服务的作用显现出来了,可以借鉴Twitter的Zippkin和Google的Dapper的实现思路。当前我们结合自身的业务架构特点,实现了一个统一的服务调度框架和名字服务中心,在业务代码无侵入的情况下,可以把业务调度链的染色数据上报和关联,实现对于单个问题的快速定位。
数据的可视化能力非常重要,需要在面向整体和面向某个业务流上都有实现。它首先体现出你对运维的理解是什么样的,从可视化Dashboard上可以看到直接的运维经验;其次基于可视化之上的数据共享,让大家对数据的理解达成一致;后利用一致化的可视化数据发挥运维的驱动能力,驱动DevOps,数据的核心价值在于此。
因此可视化的能力代表了运维的能力,可视化的程度越高,运维的能力越高。那么你现在到底可视化了哪些运维服务,并能进行度量呢?
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐
“RPA+AI”的组合可能成为未来互联网行业的一个更大的风口吗?RPA技术在工业互联网中可以发挥什么使用价值?未来五年,微软将为200万美国农村居民提供高速互联网美媒:约2亿美国选民的资料被发在互联网上互联网测试岗位的工作日常之经验分享亚马逊追赶行业热潮:在全球推互联网电视频道服务封杀微信小米:超1500家互联网公司都被该国问候过谷歌吃螃蟹,成古巴第一家互联网外企对垒互联网金融:多家银行推虚拟信用卡互联网机票销售整治再启动,所有平台都要查互联网医院首次接轨医保:诊端尚缺火候人口红利将尽:互联网公司如何经营下半场互联网产品接入支付功能如何测试?互联网手机尴尬下半场:“退烧”之后如何应对生死危机?彭博社:京东进军互联网金融市场为追赶阿里巴巴中国App广告海外遭封杀,互联网出海营销困境凸显












 sales@spasvo.com
sales@spasvo.com