
SQL Server 2014,改善的临时表缓存
作者:网络转载 发布时间:[ 2015/6/30 17:13:32 ] 推荐标签:数据库
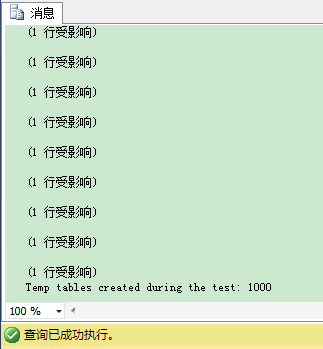
当你运行这个代码时,SQL Server需要创建1000个单独的临时表,这个从SSMS的输出窗口可以看到。
通过PRIMARY KEY约束来强制UNIQUE CLUSTERED INDEX很容易克服这个问题。在这个方式下,你没有混合使用DDL和DML语句,SQL Server后也能缓存你的临时表。
1 ALTER PROCEDURE PopulateTempTable
2 AS
3 BEGIN
4 -- Create a new temp table
5 CREATE TABLE #TempTable
6 (
7 Col1 INT IDENTITY(1, 1) PRIMARY KEY, -- This creates also a Unique Clustered Index
8 Col2 CHAR(4000),
9 Col3 CHAR(4000)
10 )
11
12 -- Insert 10 dummy records
13 DECLARE @i INT = 0
14 WHILE (@i < 10)
15 BEGIN
16 INSERT INTO #TempTable VALUES ('Woody', 'Tu')
17 SET @i += 1
18 END
19 END
20 GO
当你重新执行刚才用来跟踪相关计数器的代码,可以看到SQL Server值创建了一次临时表并重用它了:
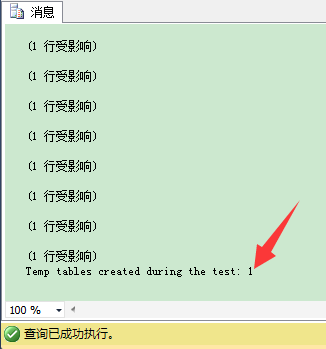
这个结论也意味着,当你创建额外的非聚集索引(Non-Clustered Indexes)时,SQL Server也不能缓存临时表,因为在你的存储过程里,你又一次混合使用DDL和DML语句。
但在SQL Server 2014里,你可以克服这个限制,因为现在你可以在CREATE TABLE语句行里创建索引。来看下面的代码:
1 ALTER PROCEDURE PopulateTempTable
2 AS
3 BEGIN
4 -- Create a new temp table
5 CREATE TABLE #TempTable
6 (
7 Col1 INT IDENTITY(1, 1) PRIMARY KEY, -- This creates also a Unique Clustered Index
8 Col2 CHAR(100) INDEX idx_Col2,
9 Col3 CHAR(100) INDEX idx_Col3
10 )
11
12 -- Insert 10 dummy records
13 DECLARE @i INT = 0
14 WHILE (@i < 10)
15 BEGIN
16 INSERT INTO #TempTable VALUES ('Woody', 'Tu')
17 SET @i += 1
18 END
19 END
20 GO
如你所见,我在创建临时表本身的时候,在临时表上直接创建2个额外的非聚集索引。又一次我们没有混合使用DDL和DML语句,SQL Server又一次可以缓存并重用你的临时表。
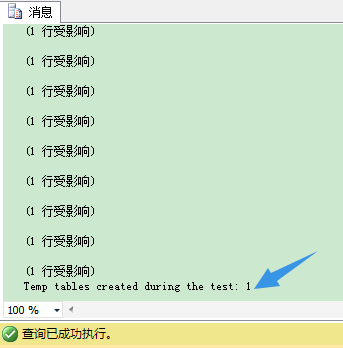
在SQL Server 2014里,在临时表上定义行内定义索引,避开混合使用DML和DDL语句,让临时表只创建一次并重用,是一个很棒的功能!
这个新功能怎样?欢迎在下面评论里告诉我。












 sales@spasvo.com
sales@spasvo.com