
Java内存分配和String类型的深度解析
作者:网络转载 发布时间:[ 2015/8/17 10:29:30 ] 推荐标签:测试开发技术 编程语言
2、String的定义方法
在讨论String的定义方法之前,先了解一下常量池的概念,前面在介绍方法区的时候已经提到过了。下面稍微正式的给一个定义吧。
常量池(constant pool)指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。它包括了关于类、方法、接口等中的常量,也包括字符串常量。常量池还具备动态性,运行期间可以将新的常量放入池中,String类的intern()方法是这一特性的典型应用。不懂吗?后面会介绍intern方法的。虚拟机为每个被装载的类型维护一个常量池,池中为该类型所用常量的一个有序集合,包括直接常量(string、integer和float常量)和对其他类型、字段和方法的符号引用(与对象引用的区别?读者可以自己去了解)。
String的定义方法归纳起来总共为三种方式:
使用关键字new,如:String s1 = new String(“myString”);
直接定义,如:String s1 = “myString”;
串联生成,如:String s1 = “my” + “String”;这种方式比较复杂,这里不赘述了,请参见java–String常量池问题的几个例子。
第一种方式通过关键字new定义过程:在程序编译期,编译程序先去字符串常量池检查,是否存在“myString”,如果不存在,则在常量池中开辟一个内存空间存放“myString”;如果存在的话,则不用重新开辟空间,保证常量池中只有一个“myString”常量,节省内存空间。然后在内存堆中开辟一块空间存放new出来的String实例,在栈中开辟一块空间,命名为“s1”,存放的值为堆中String实例的内存地址,这个过程是将引用s1指向new出来的String实例。各位,模糊的地方到了!堆中new出来的实例和常量池中的“myString”是什么关系呢?等我们分析完了第二种定义方式之后再回头分析这个问题。
第二种方式直接定义过程:在程序编译期,编译程序先去字符串常量池检查,是否存在“myString”,如果不存在,则在常量池中开辟一个内存空间存放“myString”;如果存在的话,则不用重新开辟空间。然后在栈中开辟一块空间,命名为“s1”,存放的值为常量池中“myString”的内存地址。常量池中的字符串常量与堆中的String对象有什么区别呢?为什么直接定义的字符串同样可以调用String对象的各种方法呢?
带着诸多疑问,我和大家一起探讨一下堆中String对象和常量池中String常量的关系,请大家记住,仅仅是探讨,因为本人对这块也比较模糊。
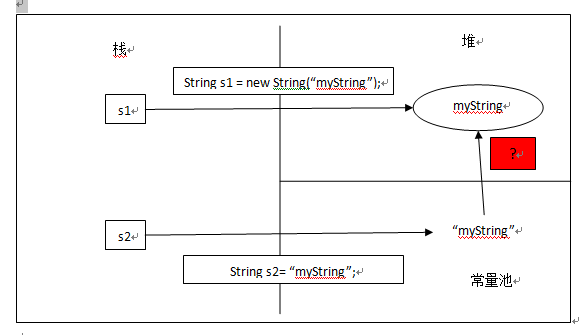
第一种猜想:因为直接定义的字符串也可以调用String对象的各种方法,那么可以认为其实在常量池中创建的也是一个String实例(对象)。String s1 = new String(“myString”);先在编译期的时候在常量池创建了一个String实例,然后clone了一个String实例存储在堆中,引用s1指向堆中的这个实例。此时,池中的实例没有被引用。当接着执行String s1 = “myString”;时,因为池中已经存在“myString”的实例对象,则s1直接指向池中的实例对象;否则,在池中先创建一个实例对象,s1再指向它。如下图所示:
这种猜想认为:常量池中的字符串常量实质上是一个String实例,与堆中的String实例是克隆关系。
第二种猜想也是目前网上阐述的多的,但是思路都不清晰,有些问题解释不通。下面引用《JAVA String对象和字符串常量的关系解析》一段内容。
在解析阶段,虚拟机发现字符串常量”myString”,它会在一个内部字符串常量列表中查找,如果没有找到,那么会在堆里面创建一个包含字符序列[myString]的String对象s1,然后把这个字符序列和对应的String对象作为名值对( [myString], s1 )保存到内部字符串常量列表中。如下图所示:
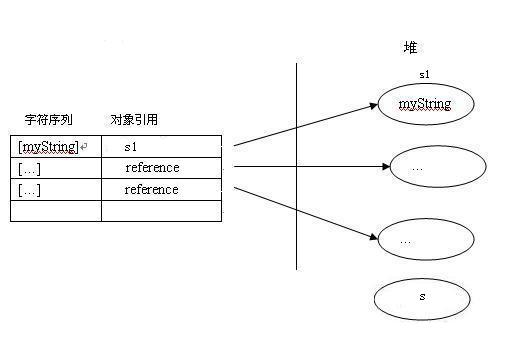
如果虚拟机后面又发现了一个相同的字符串常量myString,它会在这个内部字符串常量列表内找到相同的字符序列,然后返回对应的String对象的引用。维护这个内部列表的关键是任何特定的字符序列在这个列表上只出现一次。
例如,String s2 = “myString”,运行时s2会从内部字符串常量列表内得到s1的返回值,所以s2和s1都指向同一个String对象。
这个猜想有一个比较明显的问题,红色字体标示的地方是问题的所在。证明方式很简单,下面这段代码的执行结果,javaer都应该知道。
String s1 = new String(“myString”);
String s2 = “myString”;
System.out.println(s1 == s2); //按照上面的推测逻辑,那么打印的结果为true;而实际上真实的结果是false,因为s1指向的是堆中String对象,而s2指向的是常量池中的String常量。
虽然这段内容不那么有说服力,但是文章提到了一个东西——字符串常量列表,它可能是解释这个问题的关键。
文中提到的三个问题,本文仅仅给出了猜想,请知道真正内幕的高手帮忙分析分析,谢谢!
堆中new出来的实例和常量池中的“myString”是什么关系呢?
常量池中的字符串常量与堆中的String对象有什么区别呢?
为什么直接定义的字符串同样可以调用String对象的各种方法呢?
3、String、StringBuffer、StringBuilder的联系与区别
上面已经分析了String的本质了,下面简单说说StringBuffer和StringBuilder。
StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢?
关于StringBuffer和StringBuilder的区别,翻开它们的源码,下面贴出append()方法的实现。
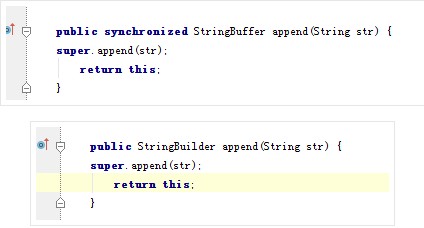
面第一张图是StringBuffer中append()方法的实现,第二张图为StringBuilder对append()的实现。区别应该一目了然,StringBuffer在方法前加了一个synchronized修饰,起到同步的作用,可以在多线程环境使用。为此付出的代价是降低了执行效率。因此,如果在多线程环境可以使用StringBuffer进行字符串连接操作,单线程环境使用StringBuilder,它的效率更高。












 sales@spasvo.com
sales@spasvo.com