
浅谈SQL语句的执行过程
作者:网络转载 发布时间:[ 2015/8/31 13:32:05 ] 推荐标签:数据库
写在前面的话:有时不理解SQL语句各个部分执行顺序,导致理解上出现偏差,或者是书写SQL语句时随心所欲,所以有必要了解一下sql语句的执行顺序。可以有时间自己写一个简单的数据库,理解会更加深入。下面写写我的一些理解,以SQL SERVER2008为例,进行说明。
先看下面这条简单SQL语句:
1 select
2 top 10 *
3 from Student
4 where age>20
这条SQL语句是否可以有下面两种理解呢
(1)先从Student表中选出age>20的数据,然后从这些数据中选择前面的10条数据。
(2)先从Student表中选出前10条数据,然后从这些数据中选择age>20的数据。
那么到底哪个是正确的呢?你可能会说,这还不容易,肯定是(1)是正确的。没错,对于这样的简单的语句,一眼能看出来,可是对于稍微复杂一些的SQL语句或者更加复杂的SQL语句,有时我们一眼看不出来了,为了能够正确分析SQL语句以及写出正确的SQL语句,有必要了解一下SQL语句各部分的执行顺序。
好了,我们再看下面的一条SQL语句:
select
distinct
top 1
Table1.id,COUNT(Table1.name) as nameCount
from Table1
inner join Table2
on Table1.id=Table2.id
where Table1.id<4
group by Table1.id
having Table1.id<3
order by Table1.id desc
其中Table1和Table2是我随便建立的两个非常简单的表,为了讲解方便,我也没有弄一些跟实际相结合的表,要不还要理解业务逻辑,干脆越简单越好,毕竟目的是为了说明SQL语句的执行顺序,Table1和Table2如下:
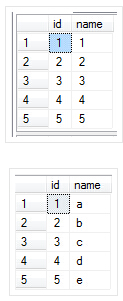
Table1 Table2
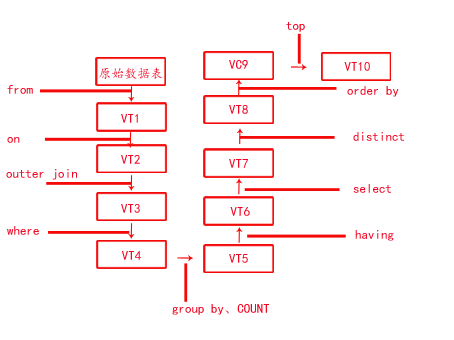
下面先给出上面的SQL语句的执行顺序,然后进行讲解:
(8) select
(9) distinct
(11) top 1 (6) Table1.id,COUNT(Table1.name) as nameCount
(1) from Table1
(3) inner join Table2
(2) on Table1.id=Table2.id
(4) where Table1.id<4
(5) group by Table1.id
(7) having Table1.id<3
(10) order by Table1.id desc
红色序号给出了执行的顺序:
(1)from:对Table1和Table2执行笛卡尔积,也是两个表的行的各种组合,共5*5=25行,生成虚拟表VT1
(2)on:选择VT1中的那些Table1.id=Table2.id的所有行,生成虚拟表VT2。
(3)inner join:这里是内部连接,直接是VT2,如果是outer join,如left join、right join、full join,那么还需要按照外部连接的规则,把VT1中没有匹配的行添加到VT2,生成VT3.
(4)where:选出VT3中Table1.id<4的表格,给虚拟表VT4.
(5)group by:按照Table1.id进行分组。
(6)COUNT:执行聚合函数,选出对应Table1.id的行数,生成的结果给虚拟表VT5
(7)having:选择VT5中Table1.id<3的所有结果,给虚拟表VT6
(8)select:选择VT6中相应的列,给虚拟表VT7
(9)distinct:将VT7中重复的行去除,生成VT8
(10)order by:将VT8的结果按照Table1.id进行排序,这里没有生成一个新的表VT9,而是生成游标VC9。
(11)top:从游标VC9的开始处选择指定的行数,这里是1行,生成虚拟表VT10.
经过上面的过程,终的SQL语句将VT10返回给用户使用。
所以以后再写SQL语句的时候,可以按照上面的顺序写SQL语句了,读SQL语句也可以按照上面的顺序去读,做到心里明白。
好了,??嗦嗦说了这么多,上个图吧(真是奇丑无比),一图胜千言,自己做个总结,也希望对大家有所帮助。












 sales@spasvo.com
sales@spasvo.com