
SQL Server实现短路径的搜索算法
作者:网络转载 发布时间:[ 2013/4/25 10:58:46 ] 推荐标签:
第2方法是:针对第1种方法的改进,是采用多源点方法,这里是以节点"p"和节点"j"为中心向外层扩展,直到两圆外切点,如图4:
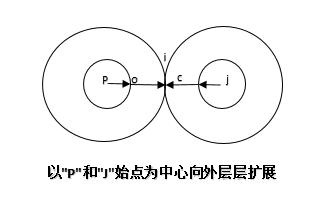
图4
实现:
在接下来,我描述在SQL Server中,如何实现。当然我这里采用的前面说的第2种方法,以"P"和"J"为始点像中心外层层扩展。
这里提供有表RelactionGraph的create& Insert数据的脚本:
use TestDB
go
if object_id('RelactionGraph') Is not null drop table RelactionGraph
create table RelactionGraph(ID int identity,Item nvarchar(50),RelactionItemnvarchar(20),constraint PK_RelactionGraph primary key(ID))
go
create nonclustered index IX_RelactionGraph_Item on RelactionGraph(Item)include(RelactionItem)
create nonclustered index IX_RelactionGraph_RelactionItem on RelactionGraph(RelactionItem)include(Item)
go
insert into RelactionGraph (Item, RelactionItem ) values
('a','b'),('a','c'),('a','d'),('a','e'),
('b','f'),('b','g'),('b','h'),
('c','i'),('c','j'),
('f','k'),('f','l'),
('k','o'),('k','p'),
('o','i'),('o','l')
go
编写一个存储过程up_GetPath
use TestDB
go
exec dbo.up_GetPath
@Node = 'p',
@RelatedNode = 'j'
go
上面的存储过程,主要分为两大部分,第1部分是实现如何搜索,第2部分实现如何构造返回结果。其中第1部分的代码根据前面的方法2,通过@Node 和 @RelatedNode 两个节点向外层搜索,每次搜索返回的节点都保存至临时表#1和#2,再判断临时表#1和#2有没有出现切点,如果出现说明已找到短的路径(经过多节点数少),否则继续循环搜索,直到循环至大的搜索深度(@MaxLevel smallint=100)或找到切点。要是到100层都没搜索到切点,将放弃搜索。这里使用大可搜索深度@MaxLevel,目的是控制由于数据量大可能会导致性能差,因为在这里数据量与搜索性能成反比。代码中还说到一个正向和反向搜索,主要是相对Node 和 RelatedNode来说,它们两者互为参照对象,进行向外搜索使用。
下面是存储过程的执行:













 sales@spasvo.com
sales@spasvo.com