
Windows和Linux换行规则的区别
作者:网络转载 发布时间:[ 2014/6/10 11:13:01 ] 推荐标签:Windows Linux 操作系统
这里看到后一行没有换行符,其他行的换行符为^M$, 使用sed处理这个文本文件,向第二行添加一些内容,再用cat -A查看:
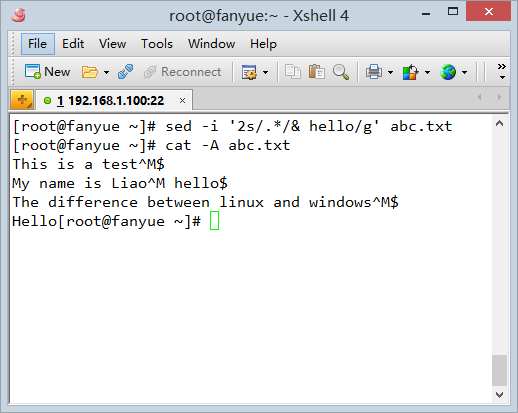
这里我用.*匹配第二行的所有内容,&表示匹配到的所有内容,在&后面我加上了一些内容,用cat -A查看发现,sed在处理替换时,如果匹配到整个行,那么匹配的内容是除了换行符$(Linux 换行符)外的所有内容,即使这个文本的换行符是^M$(windows 换行符).
因此第二行的文本被sed处理后,^M被我的正则表达式.*当作文本内容而匹配到了,而$不会被匹配,永远在行的末尾充当换行符,这样一来^M和$被拆散了。因此这一行的换行符在处理后成为了linux格式的换行符$. 用vim打开的效果如下:
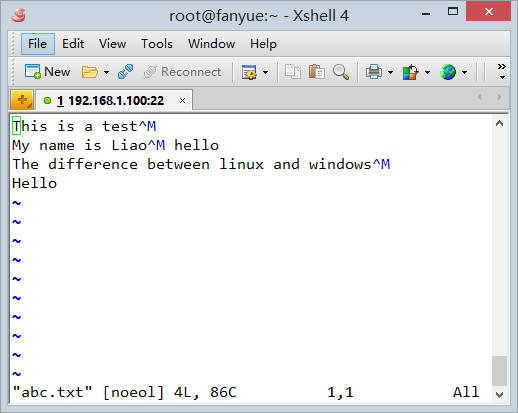
因为文件的换行符是linux和windows混杂的,vim以unix文件格式显示这个文件,文件的^M被显示出来,并且第二行的^M被sed匹配到,因而不在行尾。vim下方的[noeol]原因是后一行在windows下没有换行符,因此也没有^M.
得出结论:sed会把文件中的^M当作文件内容来处理,因此如果用sed处理windows下创建的文本文件,很有可能在处理之后显示时出现讨厌的^M. 关于其他的文本处理器如何处理windows的换行符,还有待进一步研究。
小结:
windows下创建的文件换行符为^M$,但后一行结尾没有换行符
linux下创建的文件,每一行都会以换行符$结束,包括后一行
vim打开文件时,如果文件的所有换行符都是dos格式的^M$,那么vim会自动以dos文件格式来显示文本文件,否则会以默认的unix格式显示文本,这是可能会在行的结尾出现^M的符号
wc -l是以$换行符来统计行数的,因此windows下创建的文件使用wc -l统计行数时会少一行
一个windows下创建的文件,在linux下显示正常,但是用某些文本处理命令,如sed处理后,文件的某些换行符可能会改变,造成显示不正常
sed处理文件时,会把windows换行符中的^M当作文件内容,即sed只保留$作为行末尾的换行符,因此可能会造成换行符不一致。












 sales@spasvo.com
sales@spasvo.com